n <- 30
mu0 <- 0
sd0 <- 1
mu1 <- 0
p_values_null <- rep(NULL, 140000)
for (i in c(1:140000)) {
group1 <- rnorm(n, mu0, sd0)
group2 <- rnorm(n, mu1, sd0)
test <- t.test(group1, group2, alternative = "less")
p_values_null[i] <- test$p.value
}In the current post I try to explain what appears to be a paradox: given identical data, different schools of statistics disagree about the appropriate conclusion.
Traditionally, there are two ways to interpret Probability:
1. Probability is the relative frequency of events at infinity - the Frequentist school.
2. Probability represents the degree of beliefs - The Bayesian school.
Classic hypothesis testing in the social sciences usually follows the Frequentist school, the probability of errors is calculated as the relative frequency of extreme data under the relevant hypotheses.
Distribution of p-values when the null hypothesis is true
An example for Frequentist logic in hypothesis testing is the probability of type I errors, also known as \(\alpha\): rejecting the null hypothesis when it is true.
The famous (and notorious?) 5% convention, refers to the relative frequency of significant tests when the null is true.
Let’s take infinite (140,000) samples of \(n=30\) from populations with equal means, and compare each of them with a t-test:
How many tests were significant?
length(p_values_null[p_values_null < .05])/length(p_values_null)[1] 0.05020714What if we defined \(\alpha=0.067\)?
length(p_values_null[p_values_null < .067])/length(p_values_null)[1] 0.06699286Putting it in different words, the probability of getting p-values under a certain threshold equals to that threshold. or, When population means are equal, p-values are distributed uniformly.
par(bg = '#F9EBDE')
hist(p_values_null, breaks = 50, xlab = NULL, freq = F)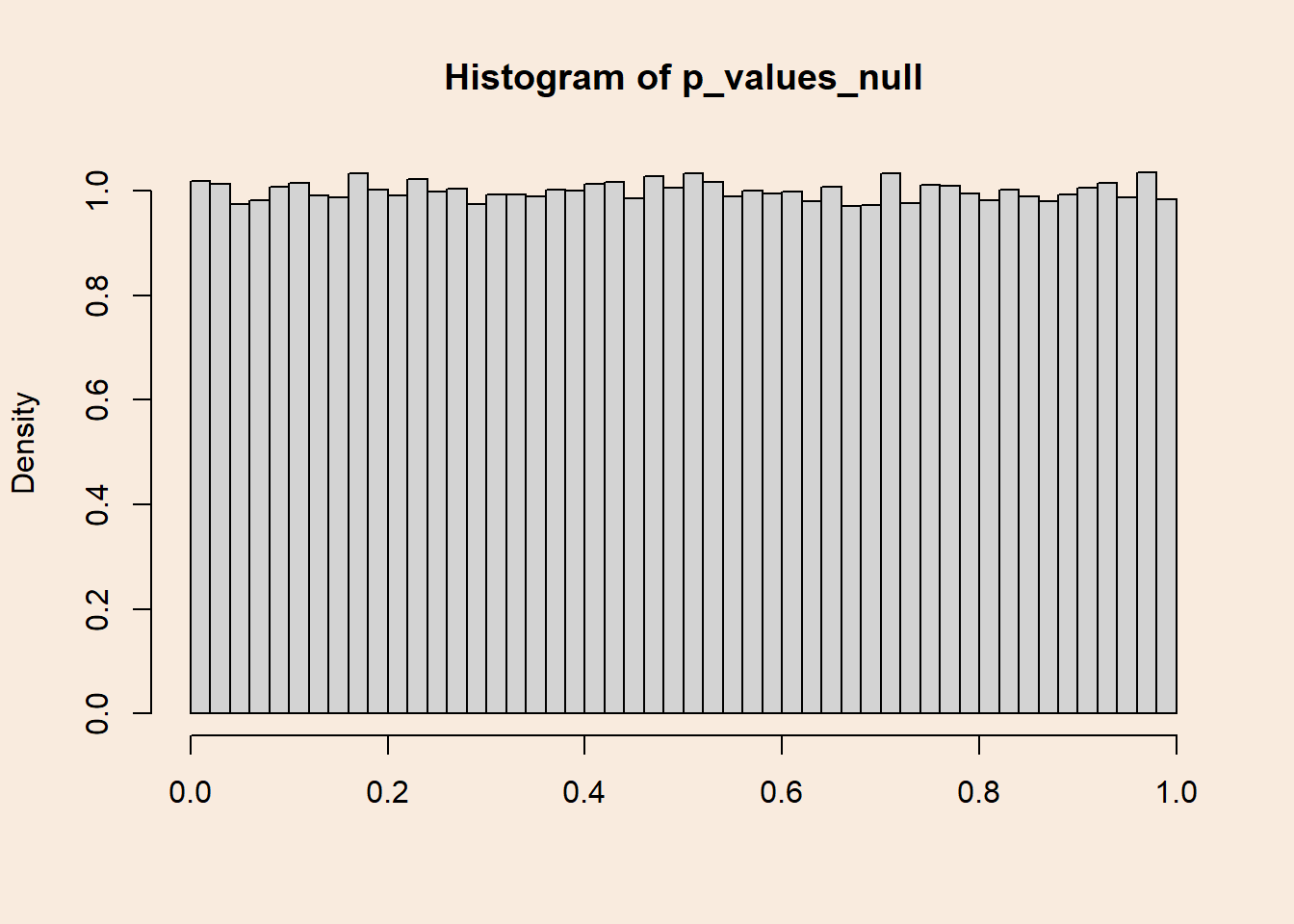
Distribution of p-values when the null hypothesis is false
What happens when population means are not equal? The probability of detecting an existing effect (e.g. getting a significant result) is called Power. Naturally, statistical Power is larger for larger differences between populations means.
Lets simulate yet again infinite (140,000) t-tests, this time between samples from populations with difference of means of 0.65.
Distribution of p-values with 80% power
n <- 30
mu0 <- 0
sd0 <- 1
mu1 <- 0.65
p_values_80 <- rep(NULL, 140000)
for (i in c(1:140000)) {
group1 <- rnorm(n, mu0, sd0)
group2 <- rnorm(n, mu1, sd0)
test <- t.test(group1, group2, alternative = "less")
p_values_80[i] <- test$p.value
}What is the probability of getting a significant result?
length(p_values_80[p_values_80 < .05])/length(p_values_80)[1] 0.80015How does the distribution of p-values look when there is 80% Power (probability of 0.8 of getting a significant result)?
par(bg = '#F9EBDE')
hist(p_values_80, breaks = 50, xlab = NULL, freq = F)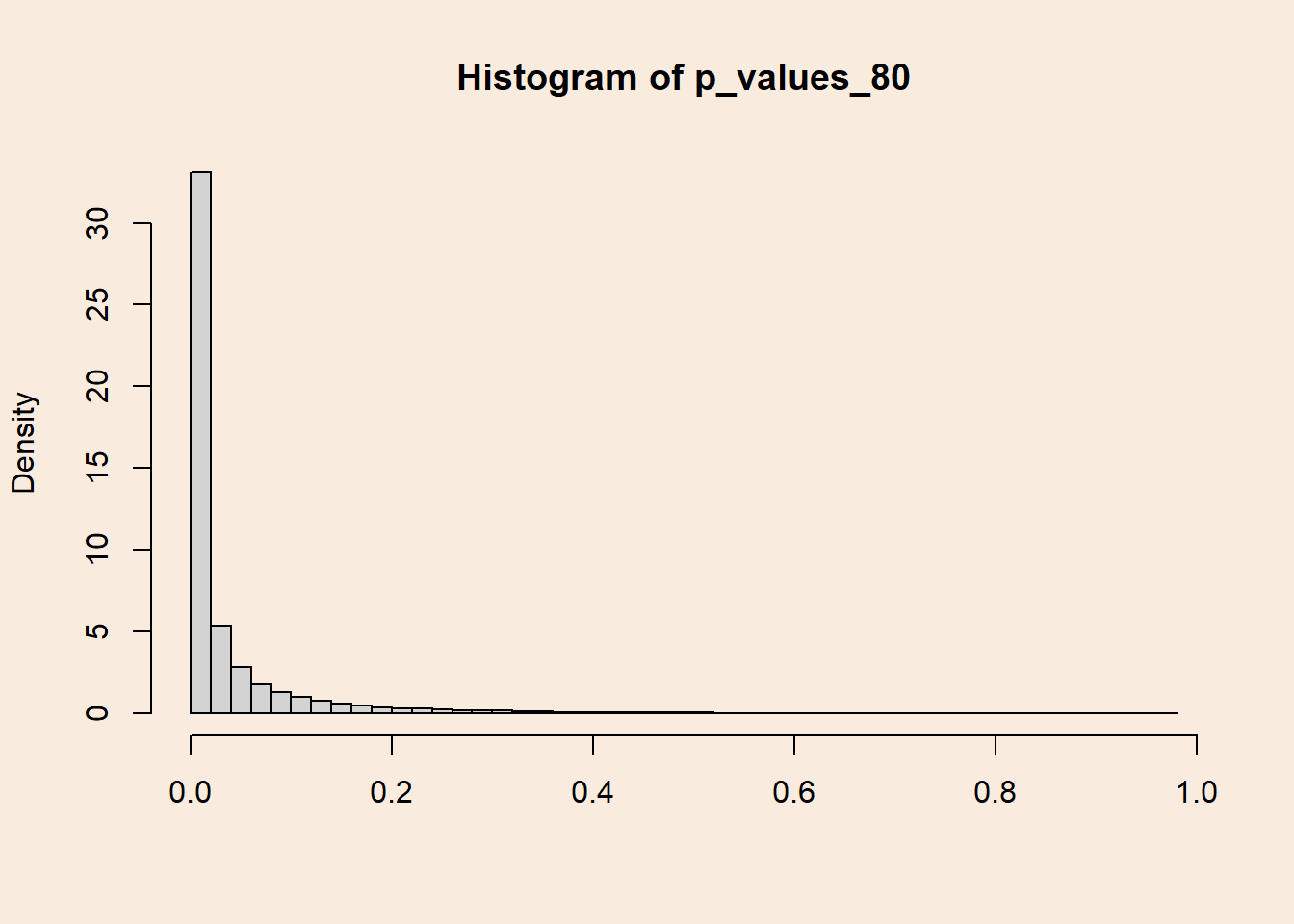
Smaller p-values are more probable, and the uniform distribution from before “gets skewed”.
Distribution of p-values with 99% power
Increasing the difference between population means causes the p-values distribution to get more and more skewed.
n <- 30
mu0 <- 0
sd0 <- 1
mu1 <- 1.0376218
p_values_99 <- rep(NULL, 140000)
for (i in c(1:140000)) {
group1 <- rnorm(n, mu0, sd0)
group2 <- rnorm(n, mu1, sd0)
test <- t.test(group1, group2, alternative = "less")
p_values_99[i] <- test$p.value
}
length(p_values_99[p_values_99 < .05])/length(p_values_99)[1] 0.9899And the distribution of p-values:
par(bg = '#F9EBDE')
hist(p_values_99, breaks = 100, freq = F, xlab = NULL)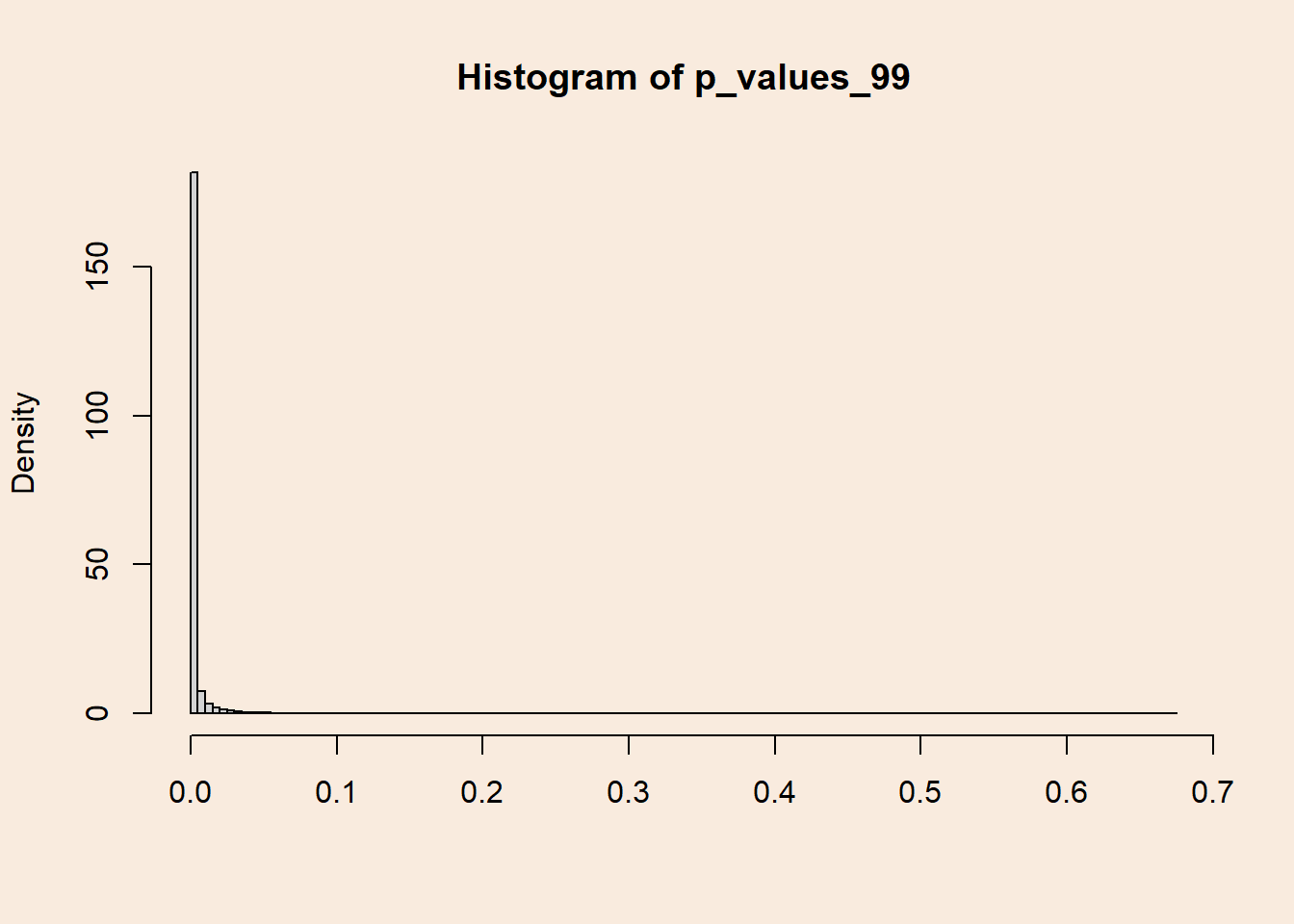
Reversing the conditionality

As we said before, p-values represent the probability of getting certain data when the null hypothesis is true. What if we looked at it from the other side? What is the probability that the null hypothesis is true, given a certain p-value?
In the Frequentist school, this question seems weird: what is the relative frequency at infinity of the null hypothesis being true? That is, out of infinite worlds, in how many of them the null is true?
Switching our perspective to be Bayesian, assigning probabilities to hypotheses becomes less weird. That is because Bayesians see probability as a measure of confidence in some statement/model/possible world.
As it’s name suggests, the Bayesian interpretation of probability is rooted in the Bayes theorem for conditional probabilities:
\[ p(A/B)= \frac {p(A) \cdot p(B/A)}{p(B)} \]
Confidence in \(A\) given the occurrence of \(B\) is proportional to the product of the prior confidence in \(A\) and the conditional probability of \(A\) on \(B\) - also called the Likelihood of \(A\).
Important
Bayes’ theorem is not a matter of interpretation. it can be derived from the basic probability axioms. It is linked with the interpretation of probability as a measure of confidence in statements because it defines the procedure of belief updating.
Re-phrasing the theorem, it is possible to formulate the posterior probability of a hypothesis given some observed data:
\[ p(hypothesis/data)= \frac {p(hypothesis) \cdot p(data/hypothesis)}{p(data)} \]
Another possibility of conceptualize the Bayes mindset is seeing the posterior probability of the hypothesis as an update to the prior probability of it.
Bayes theorem also enable the comparison of two hypotheses using the ratio between the posteriors:/ \[ \frac{p(hypothesis \, 1/data)}{p(hypothesis \, 2/data)}= \frac {\frac {p(hypothesis \, 1) \cdot p(data/hypothesis \, 1)}{p(data)}}{\frac {p(hypothesis \, 2) \cdot p(data/hypothesis \, 2)}{p(data)}} \]
Cancelling the annoying denominator yields the following: \[ \frac {p(hypothesis \, 1) \cdot p(data/hypothesis \, 1)}{p(hypothesis \, 2) \cdot p(data/hypothesis \, 2)} \]
The ratio of posterior probabilities equals to the product of the prior ratio and the likelihood ratio. When this value is bigger then 1, it can considered as evidence in favor of Hypothesis 1.
Posterior probability of hypotheses given p-values
Using Bayes theorem, it is now possible to construct a posterior probability for each of the original hypotheses, given an observed p-value.
Likelihood
What is the probability of p-values given each hypothesis? we actually answered this question earlier when we visualized the density distributions of p-values.
For example, the probability of observing a p-value between 0.03 and 0.04 given the null hypothesis is:
data.frame("p" = p_values_null) |>
ggplot(aes(x = p)) +
geom_density(alpha = .6, fill = "#815854") +
geom_area(aes(x = stage(p, after_stat = oob_censor(x, c(0.03, 0.04)))), stat = "density", fill = "gray") +
annotate("text", x = 0.14, y = 0.5, label = "italic(p) == 0.0099",
parse = TRUE) +
geom_vline(xintercept = 0.03, color = "black", linewidth = 0.7) +
geom_vline(xintercept = 0.04, color = "black", linewidth = 0.7) +
scale_x_continuous(breaks = seq(0, 1, 0.05)) +
theme_classic() +
labs(y = "", x = "P-Value", title = "Density distribution of p-values under the null hypothesis",
subtitle = "Gray area represents the probability of p between 0.03 and 0.04") +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(family = "serif", size = 16, hjust = 0.5),
plot.subtitle = element_text(family = "serif", size = 13, hjust = 0.5),
plot.background = element_rect(fill = "#F9EBDE"),
panel.background = element_rect(fill = "#F9EBDE"))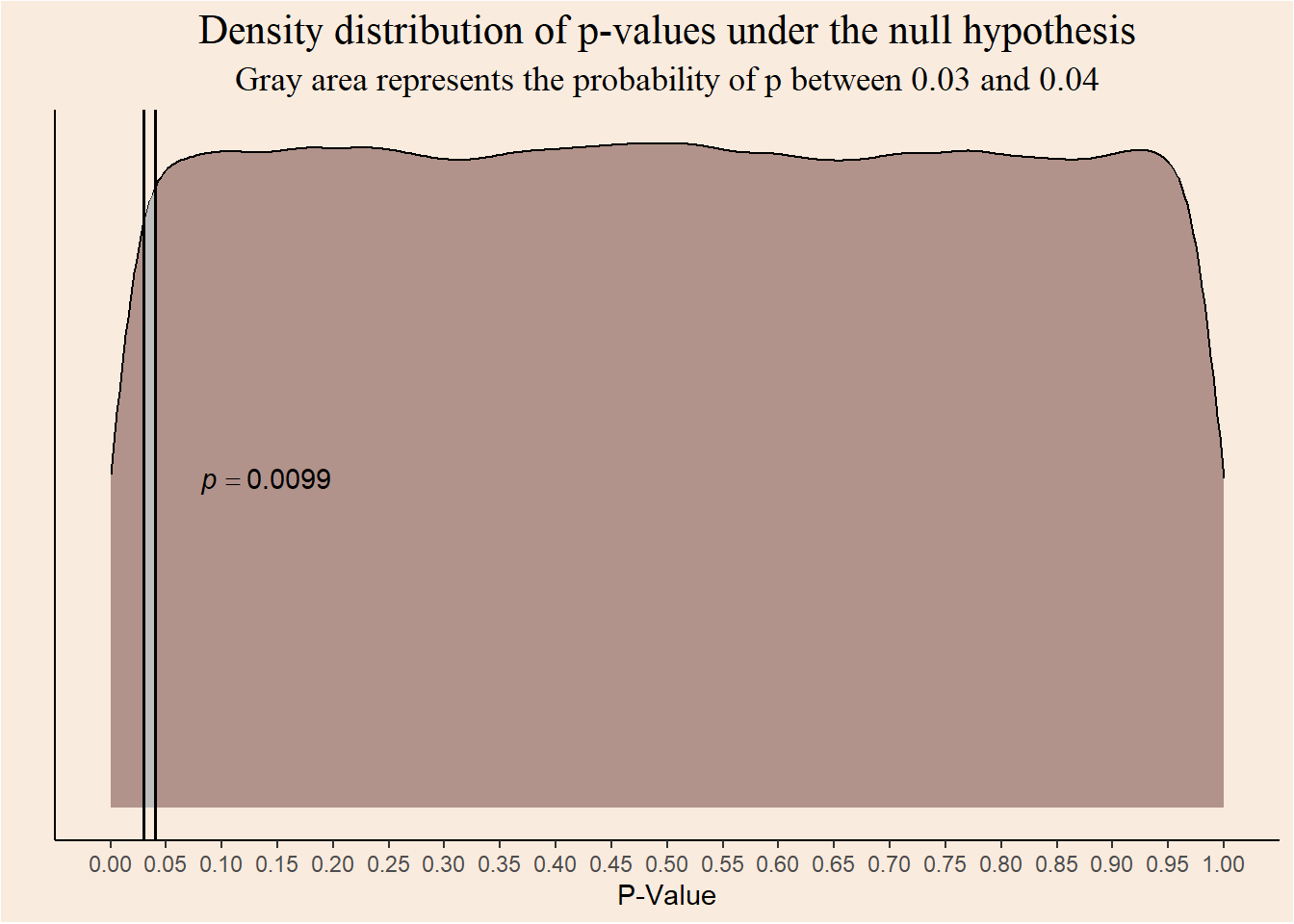
The probability of observing the same range of p-values when the effect size is \(0.65\) is:
data.frame("p" = p_values_80) |>
ggplot(aes(x = p)) +
geom_density(alpha = .6, fill = "#815854") +
geom_area(aes(x = stage(p, after_stat = oob_censor(x, c(0.03, 0.04)))), stat = "density", fill = "gray") +
annotate("text", x = 0.14, y = 8, label = "italic(p) == 0.0437",
parse = TRUE) +
geom_vline(xintercept = 0.03, color = "black", linewidth = 0.7) +
geom_vline(xintercept = 0.04, color = "black", linewidth = 0.7) +
scale_x_continuous(breaks = seq(0, 1, 0.05)) +
theme_classic() +
labs(y = "", x = "P-Value", title = "Density distribution of p-values when the effect size is 0.65",
subtitle = "Gray area represents the probability of p between 0.03 and 0.04") +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(family = "serif", size = 16, hjust = 0.5),
plot.subtitle = element_text(family = "serif", size = 13, hjust = 0.5),
plot.background = element_rect(fill = "#F9EBDE"),
panel.background = element_rect(fill = "#F9EBDE"))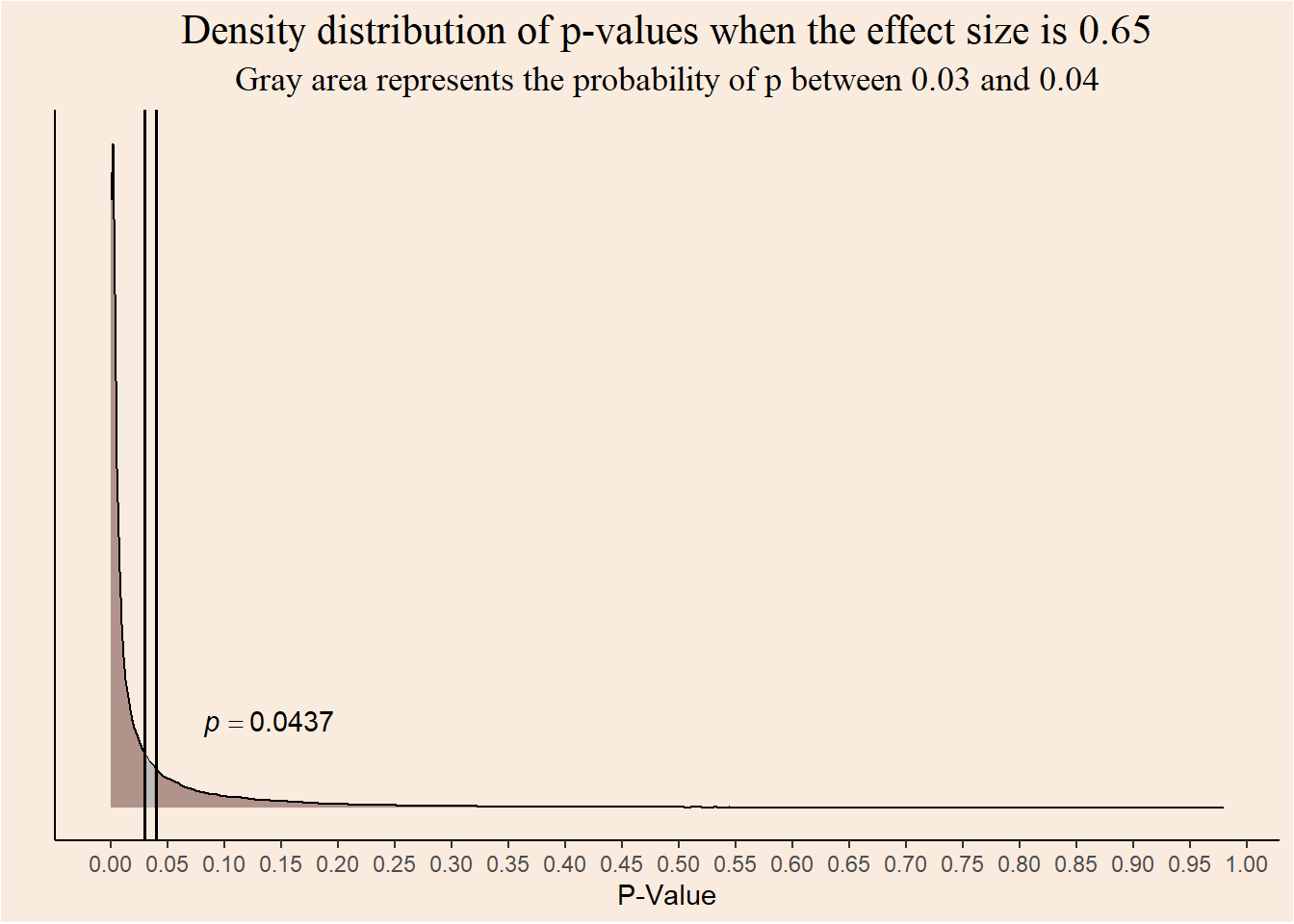
And for effect size of \(1.03\)?
data.frame("p" = p_values_99) |>
ggplot(aes(x = p)) +
geom_density(alpha = .6, fill = "#815854") +
geom_area(aes(x = stage(p, after_stat = oob_censor(x, c(0.03, 0.04)))), stat = "density", fill = "gray") +
annotate("text", x = 0.14, y = 376, label = "italic(p) == 0.0056",
parse = TRUE) +
geom_vline(xintercept = 0.03, color = "black", linewidth = 0.7) +
geom_vline(xintercept = 0.04, color = "black", linewidth = 0.7) +
scale_x_continuous(breaks = seq(0, 1, 0.05), limits = c(0, 1)) +
theme_classic() +
labs(y = "", x = "P-Value", title = "Density distribution of p-values when the effect size is 1.03",
subtitle = "Gray area represents the probability of p between 0.03 and 0.04") +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(family = "serif", size = 16, hjust = 0.5),
plot.subtitle = element_text(family = "serif", size = 13, hjust = 0.5),
plot.background = element_rect(fill = "#F9EBDE"),
panel.background = element_rect(fill = "#F9EBDE"))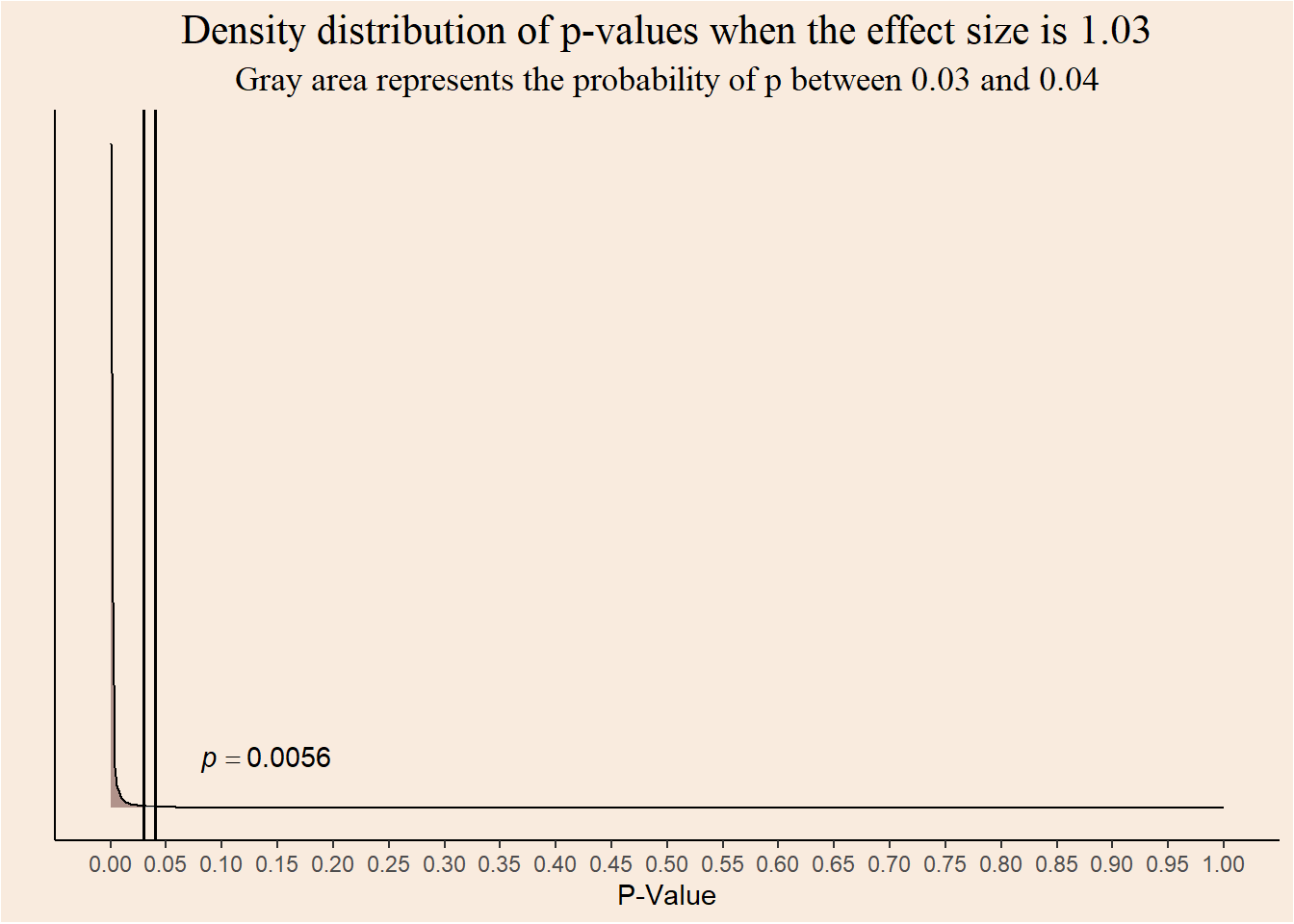
The probability of getting a p-value in the range of \([0.03,0.04]\) is lower for greater effect sizes.
Prior
Explicitly incorporating prior knowledge into statistical modelling is a great strength of Bayesian analysis. But, in order to keep things simple, I will stay agnostic and assign each hypothesis an equal prior probability. This is known as a Flat prior.
ggplot(data.frame(x = c(0, 1.5)), aes(x)) +
stat_function(fun = dunif, geom = "area", args = list(min = 0, max = 1.5), fill = "#815854") +
scale_x_continuous(breaks = seq(0, 1.5, 0.1)) +
labs(x = "Effect Size", y = "", title = "Each effect size has equal prior probability") +
theme_classic() +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(family = "serif", size = 16, hjust = 0.5),
axis.title.x = element_text(family = "serif", size = 11),
plot.background = element_rect(fill = "#F9EBDE"),
panel.background = element_rect(fill = "#F9EBDE"))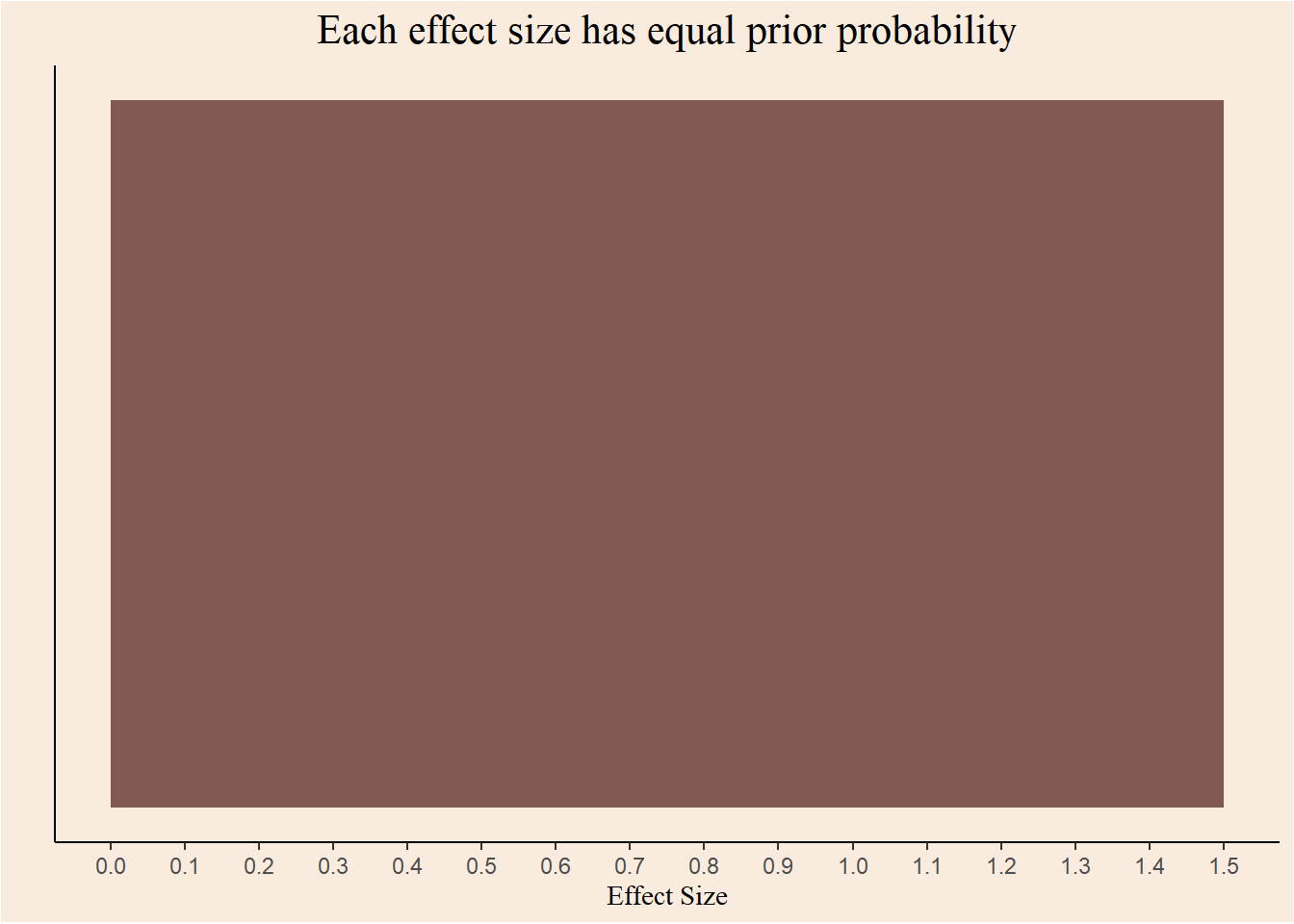
In this case the prior ratio cancels out and posterior ratio is equal to the likelihood ratio.
Rejecting the null?
Given p-value between 0.03 and 0.04, should we reject the null hypothesis or not?
As good Frequentists, we should see all p-values under the pre-defined alpha of 0.05 as evidence against the null hypothesis.
But, as good Bayesian we should ask ourselves, Given \(0.03 \le p \le 0.04\), what is more probable? effect size of \(0\) or \(1.03\)?
Defining the the flat prior:
prior_null <- 0.5
prior_1.03 <- 1 - prior_nullDefining the likelihood of p-values in the given range, under each hypothesis:
likelihood_null <- length(p_values_null[p_values_null >= 0.03 & p_values_null <= 0.04])/length(p_values_null)
likelihood_1.03 <- length(p_values_99[p_values_99 >= 0.03 & p_values_99 <= 0.04])/length(p_values_99)What is the posterior ratio?
(posterior_ratio <- (prior_null * likelihood_null)/(prior_1.03 * likelihood_1.03))[1] 1.771684Given a p-value between 0.03 and 0.04, an effect size of \(0\) is 1.77 more probable then effect size of \(1.03\)!
So, what is the answer???
What is the solution to this paradox? who is right? is statistical hypothesis testing is broken?
The source of the current disagreement is the interpretation of probability. Frequentists insist that hypotheses are True or False. There is no place for degrees of confidence in statements. Bayesians assign probability to hypotheses and statements themselves.
Whether you find yourself in the first camp, or in the second camp, remember:
All models are wrong (George Box)
This is our superpower!
